


说真的,最近一条技术新闻有点“炸”。DeepSeek的最新v3.2版本,悄悄扔了一颗“暗雷”:它公开支持了一种叫TileLang的GPU语言。这不光没在论文里提细节,只在公告里提了下,却引得圈内大神们接力讨论。到底咋回事?
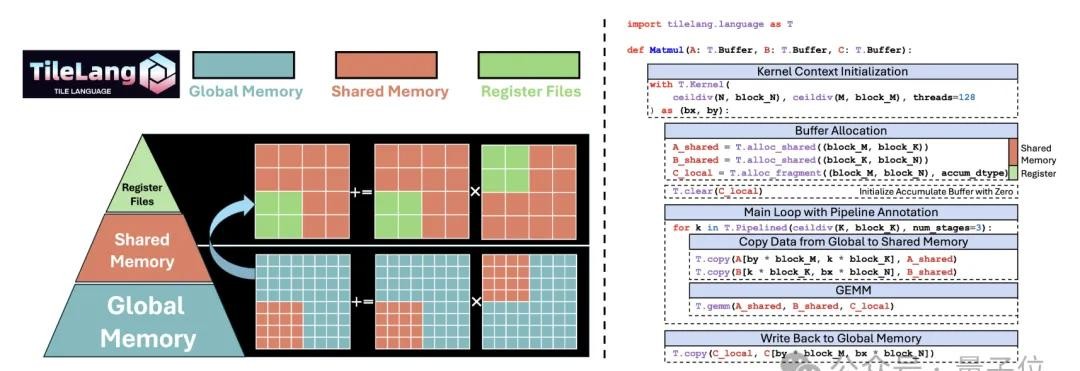
简单的讲,TileLang是一种专门为GPU优化的编程语言。性能很爆,直接对标英伟达的CUDA。不少开发者试了这语言后,纷纷表示:不但写代码效率高,性能还杠杠的。举个简单例子,就有人用不到100行代码搞出了比FlashAttention 2原版快30%的算子实现。你说强不强?
更值得大家注意的是,TileLang彻底拥抱了国产计算生态,连华为昇腾都坐不住了,第一时间跑出来说“支持”。而DeepSeek也没闲着,直接把TileLang用到了自己v3.2的核心功能里,这举动简直让人感叹“双向奔赴,有来有回”。

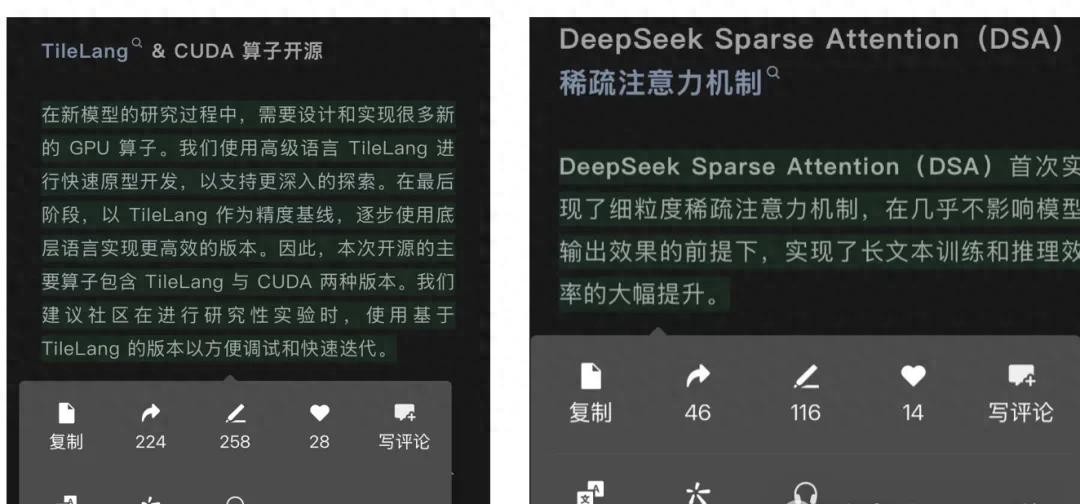
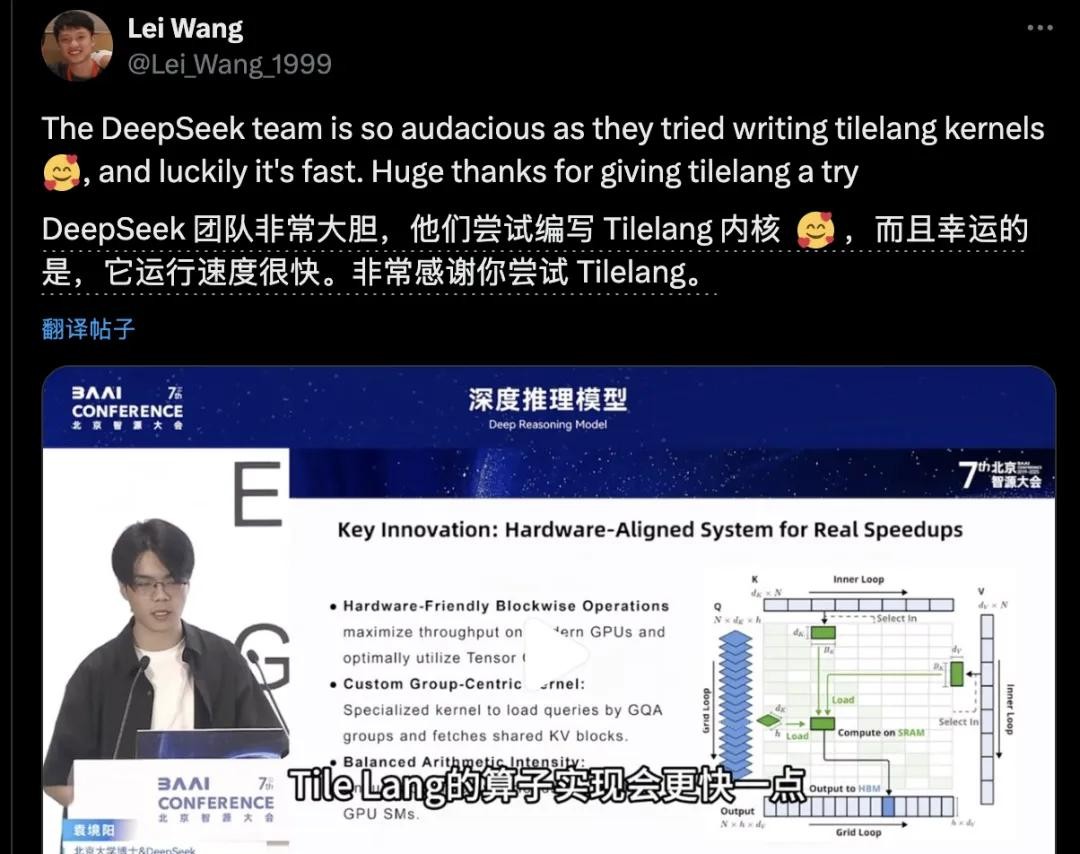
事情还得回顾以前,就在几个月前,在一个国内知名大会上,DeepSeek和TileLang第一次“官宣”合作关系。当时北大的一些博士和研究员出面做报告,详细讲了TileLang怎么优化算子开发。据说,用TileLang改造某些功能模块后,代码量能从500多行直接砍到80行,同时性能还不掉队。别说,这效率听起来确实可以。
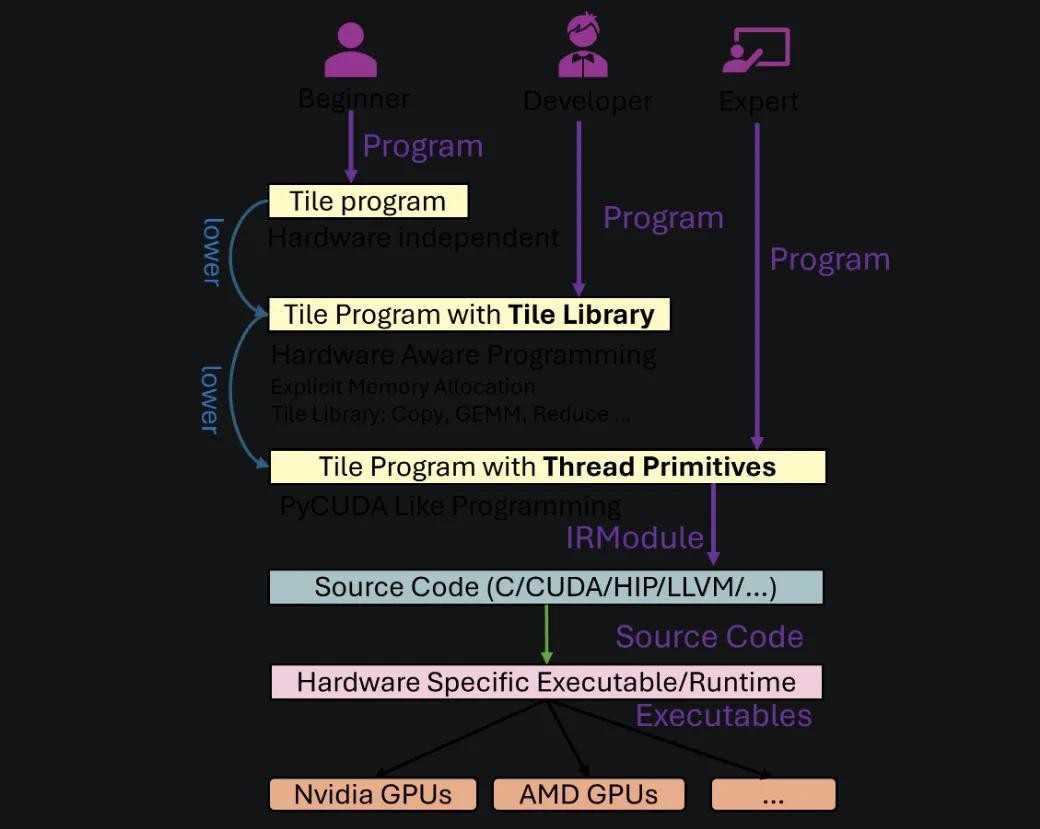
今年1月份,TileLang语言才在GitHub上正式开源,到目前被标星接近两千。这语言是由北大团队主导开发的,包括几个博士生、高级研究员,全是技术圈的硬核人物。核心设计是什么呢?一句话总结:它能让开发者专注于搞创意、写算法,让底层绕弯子调参数这种事交给编译器搞定。说白了,就是替程序员省脑,直接对准性能。

哪怕是一个初学者小白也能用,因为它设计了几种不同复杂度的编程接口。从高层逻辑到硬件无关操作,再到底层线程控制,它都支持。这么贴心的语言,你说能不能火?
DeepSeek这一波用TileLang不只是打实验,还直接验证它真能拿来搞模型训练优化。它的公告里就写了,用TileLang跟传统方法比,开发速度更快,数据缓存效率也高;尤其是在一些核心机制上,表现堪称亮眼。
大家看,这事就挺有意思了。国产语言和国产算力生态,都开始在一些高精尖领域像样地玩起结合了。而DeepSeek敢于试新语言,也确实挺有想法。别忘了,这语言刚开源几个月,很多开发者还在摸索中,而DeepSeek直接用来搞核心产品开发,这步棋够大胆。技术圈里有人评价说,这种敢于吃螃蟹的精神,不仅值得点赞,还会推动国产技术走得更远。
话说回来,你觉得国产语言未来能替代国外巨头产品吗?像CUDA这种“技术霸主”,TileLang还有不少路要走。但有个开始,总是好事吧?

总之一句话:国产技术在发力了,接下来就看它能不能爬过高墙,坚持到最后了。期待TileLang后续搞出更多好玩的成果。


网友评论