


中国的AI公司又出新招,这次真的挺牛。大家应该很多朋友都听说过DeepSeek吧?一个中国的人工AI智能公司,在2025年9月底他们搞了个大动静——发布了一个新模型,叫V3.2-Exp。说是啥意思?实验性的,但打出了“稀疏注意力”这么个技术牌。结果,这一技术让API服务成本直接砍掉了一半多。便宜到这程度,你猜硅谷那些巨头紧张不紧张?
咱先说这个稀疏注意力,到底玄学在哪儿。据报道啊,传统Transformer模型,用的是“密集注意力”。厉害是厉害,但计算量吓人,每句话的每个字都要跟其他所有字“对话”,基本成了精细化过头的“事妈”。而DeepSeek呢?他们的新技术有点儿节约型社会的意思,它就挑重点字看,不是什么都管,搞个“前置token”的选择清单出来。这么一来,计算复杂度直线降,从二次方直接干到了线性,算得快了,还省钱。

更妙的是,它不止省功夫,还能处理长文本。以前一句两百字的,模型可能就乱套了,现在?长度翻倍也没压力。想想看,那些需要啰嗦、写论文的长篇需求,是不是被摸透了?而且,它这套可以搭配有限硬件用,不一定非得高端芯片支持,挺接地气。你要问为啥这么设计?还不是因为国内芯片条件卡脖子,人家研发直接在限制下找路子,别说,效果还真挺行。
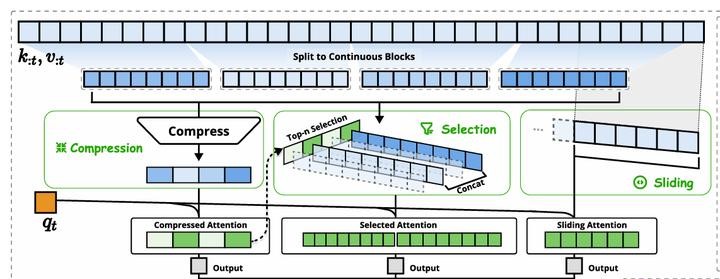
可这成本降了,有啥意义呢?不少人觉得,这是商业竞争的一步狠棋。对比OpenAI、谷歌这些大佬,DeepSeek用技术把成本削,结果大幅降低API价格。价格问题在企业客户这边特别灵,是真的钱能决定事儿。一些小公司的预算有限,谁不爱低价好用的服务?
不过便宜归便宜,DeepSeek的做法又不是单纯价格战,这点挺聪明。它从底层优化,用技术建立护城河。这可不是一时半会儿能轻松被复制的。所以说,他们这步棋,相当于抢时间+圈铁粉。
那影响有没有?当然有。业界关注的,不只是DeepSeek一家火了,而是它证明了一条新思路:架构真的能重新定义效率。原来那个“密集注意力”模式的瓶颈,明摆着暴露了。很多团队估计得琢磨,是不是也得向稀疏模型方向转转了?
还有,别老盯着技术,好些人盯着市场格局。自从DeepSeek上次几个版本闹出声儿后,美国那边不少AI圈的哥们已经高度警惕。什么原因呢?很简单,中国出手够快够狠,对价格敏感的商业客户自然转向了。毕竟,技术再高冷,省钱才是王道。
其实,更深一层的故事,是中国AI企业在逆境中练出的本事。自己芯片供应不稳,资源条件有限,照样逼着创新出东西。这种抗打击能力,全球能做到的也不多吧。你再换位思考一下,如果在芯片资源比拼里翻不过别人墙头,那就从别的地方绕过去,这些企业挺能折腾。
不过,说到未来,说实话,也没那么轻松。DeepSeek的这款模型虽然叫“实验性”,但听这名字就知道,意味着还有不少功能要验证。比如,它长文本行,那复杂任务呢?有没有缺点?目前还得多场景试。
生态系统也差着点意思。你说谷歌、OpenAI,人家的开发者社区和生态建设,那是几年工夫堆出来的护城河。DeepSeek呢?现在只有小范围名气,后续得花钱、花心思拉团队、绑用户才行。
另外,别忘了监管问题。各国对AI越来越严苛,像算法透明度、数据安全合规,不搞好直接踢出市场,后果很严重。做生意的,永远别以为技术领先能跑赢天下,还有政治、法律、市场多重门槛。
未来路怎么走,不好说。但可以肯定一点,效率升级这条路,不管是DeepSeek还是后来者,都得持续深挖。技术竞争跑得快,不一定结局赢,但慢了,一定完。
得,今天聊的够多,你怎么看?
网友评论